

Reality Check: Local Models Instead Of Expensive APIs?
Can one use an open-weight model on their laptop for everything?

We have heard for months now that OpenAI and Anthropic burn money on compute. In the months before both confidentially filed for their trillion-dollar IPOs, they announced a strong shift towards consumption-based pricing. It is a goal. The consequences are dramatic. With GitHub Copilot moving every user to token-based billing on June 1, the seat price stayed the same but the real cost did not: developers running agentic sessions are reporting projected increases of ten to fifty times, and the multiplier on a frontier model like Claude Opus 4.7 was raised from 7.5x to 27x for existing subscribers. Anthropic keeps on changing the quotas on Claude Code, and the latest models have been observed to have unstable performance and quality degradation. One can speculate that it could be due to quantisation or other changes to save on compute. Anthropic, of course, states that it absolutely does not do this intentionally, and that these are just side effects of enforcing guardrails through post-training and of misrouting.
One thing is clear. If any predictions of Dario Amodei are coming true, then it is the low-wage underclass one. Only here, low wage means the wage is too low to pay for the tokens, and the low-wage underclass is everyone who is not a massive corporation that can afford their enterprise price tag.
In this situation, the opinions of people are split: some say who cares, I will just run local models; others say let us use Chinese models, they are just as good; and the third ones just prepare to pay more.
In this article I am going to discuss what is realistic and what is not in terms of running local models and what the trade-offs are for quality, price, and speed.
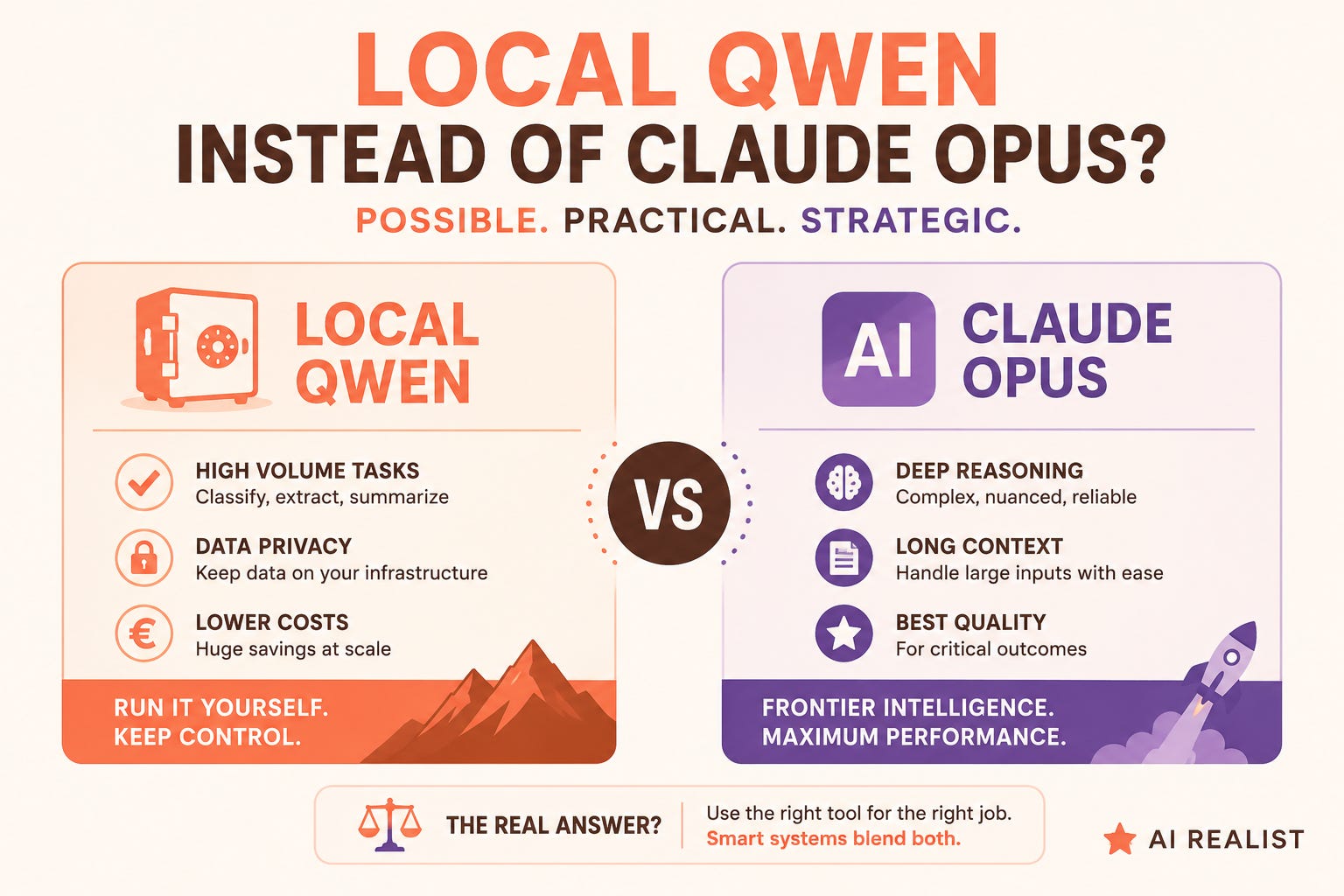
Running Local Models
This is probably one of the most common arguments. Who needs Opus-4.8 when we have Qwen-3.6? I have to be real with you directly. Unless you happen to have racks of DGX stations in the basement, you will always have a qualitative loss. In fact, you will lose quite a bit of quality running local models, if you means a mere mortal who does not have a B300 Blackwell Ultra with 288GB of memory (or even the previous-generation H200 with 141GB).
To put it into perspective, the most advanced open-weight model in its full form is currently DeepSeek-V4-Pro. It has 1.6 trillion parameters, 49 billion active per token, shipped in mixed FP4 and FP8 precision, which is its native trained format, not a degraded quant. In order to run it as is, you need roughly eight Nvidia Blackwell B200 GPUs, about 1.5TB of VRAM, or four of the newer Blackwell Ultra B300s. An Nvidia DGX B300 system runs 300,000 to 350,000 dollars, somewhere around 280,000 to 320,000 euro. This is the model that the DeepSeek lab evaluated and published, and about which they write in their technical report that it “trails state-of-the-art frontier models by approximately 3 to 6 months.”
A similar situation applies to other state-of-the-art open-weight models, Kimi K2.6 and Qwen-3.6. Kimi K2.6 is open weight but around a trillion parameters, so it is just as out of reach. Qwen-3.6 is also open weight, but it comes in smaller sizes too, and its 35B variant will actually run locally.
The one you can potentially manage to run locally is MiniMax. Its 230-billion-parameter M2.5, with 10 billion active, has been run on a single Nvidia DGX Spark in a quantised build at around 26 tokens per second. But again, that is a DGX Spark at roughly 4,000 euro each, two if you want headroom, and only a quantised version. So no, running anything remotely comparable to Sonnet or Opus is out of reach, even after investing 8,000 euro in your local setup.
Hardware requirements
First of all, you need hardware that is strong enough for it. While you can probably run and even do something with a 1.7B Qwen model, let us be honest, the utility of it will be very low. Particularly if you are not a hardcore programmer. In general, small models are most likely to be useful for experienced programmers who know very well what to request from the model.
And by that I do not mean one big detailed prompt. A small local model will struggle to hold a large, multi-part instruction in a single go. So the programmer has to split the task into many small, precise prompts and drive it step by step. Instead of saying “write a program that reads Excel, makes diagrams out of it and presents them as HTML on a website,” the coder breaks it down. First, set up Python with a dedicated virtual environment and use Poetry for package management. Then add pytest. Then read the Excel file with pandas. Then plot the diagrams with matplotlib. Then build the frontend in React and TypeScript, with the backend in Python. Each step is a separate prompt, and after each one they validate the output and fix it before moving to the next.
AI Realist is turning 1 year this month!
Only this week new subscribers get a free 7-day trial of AI Realist. Full access, no commitment. Cancel before the week is up and you pay nothing.
Anti-hype enterprise AI coverage, weekly radar briefings, investigative pieces, materials from the OpenClaw workshop and other trainings. Try it and see.
Keep reading with a 7-day free trial
Subscribe to AI Realist to keep reading this post and get 7 days of free access to the full post archives.