

Synthetic Datasets for Applied AI
Inspired by ACL Tutorial on Synthetic Datasets

I attended a fantastic tutorial on synthetic datasets by Graham Neubig and his team. You can find all the slides here.
The first free part of this post gives an overview of key learnings from the tutorial.
The second, paid part will translate these learnings into real-world applications for industry—covering how to use synthetic data in your RAG bots, agentic AI, and other typical deployments.
Why synthetic datasets?
Synthetic datasets are booming. They are used at nearly every stage of foundational model development—and in many of the systems built on top of them.
They fill the gap where other methods like web scraping or manual annotation fall short. They're relatively clean, much cheaper than human labeling, task-specific, and size-controllable. But they come with trade-offs: synthetic data often lacks realism. Unlike real-world data, it typically doesn’t include long-tail edge cases. Overtraining on synthetic data can distort distributions and even lead to model collapse.
That’s why robust evaluation pipelines are crucial.
How to evaluate synthetic data
The tutorial distinguishes between two types of evaluation:
Extrinsic – Check if a downstream task improves. For example, does adding synthetic parallel texts help a translation model perform better?
Intrinsic – Analyze the data itself. For example, are the question–answer pairs accurate?
Those two often don’t align. A dataset can be inaccurate but still improve performance. LLMs don't care much about truthfulness. Diversity matters more than accuracy. You can include false examples like “2+2=5” or “the Earth is the fifth planet from the sun” and the model might still learn something useful. A-lie-gned by design.
Cost vs. quality
Using the largest proprietary model will generate higher-quality synthetic data, especially for complex reasoning but it’s expensive. You won’t be able to generate millions of examples with it. That’s a practical trade-off to consider.
Interestingly, synthetic datasets can be more creative and diverse than crowdsourced data. Think beyond Mechanical Turk: language models are surprisingly inventive.
5 types of synthetic data generation
The tutorial outlines five main approaches:
Sampling-based generation
Back-translation
Transformation of existing data
Human-AI collaboration
Symbolic generation
Most are self-explanatory, except perhaps back-translation. Originally from machine translation, this technique involves generating an output and then asking the model to recover the original input—reversing the direction. It’s been extended to instruction tuning: give the model an output and ask what instruction could have led to it.

Filtering: correctness, quality and most importantly - diversity
A key insight: you need to filter for correctness and quality. But most importantly, you filter for diversity and only secondarily for accuracy. You want to eliminate examples that are too semantically similar to each other. Models benefit more from diverse signals than from clean ones.
Where synthetic data is used
It’s everywhere:
Pretraining – e.g., verbalizing non-linguistic data
Distillation / supervised fine-tuning – especially helpful in domain adaptation
Reinforcement learning – for reward modeling and feedback
Evaluation and testing – synthetic adversarial prompts, benchmarks, etc.
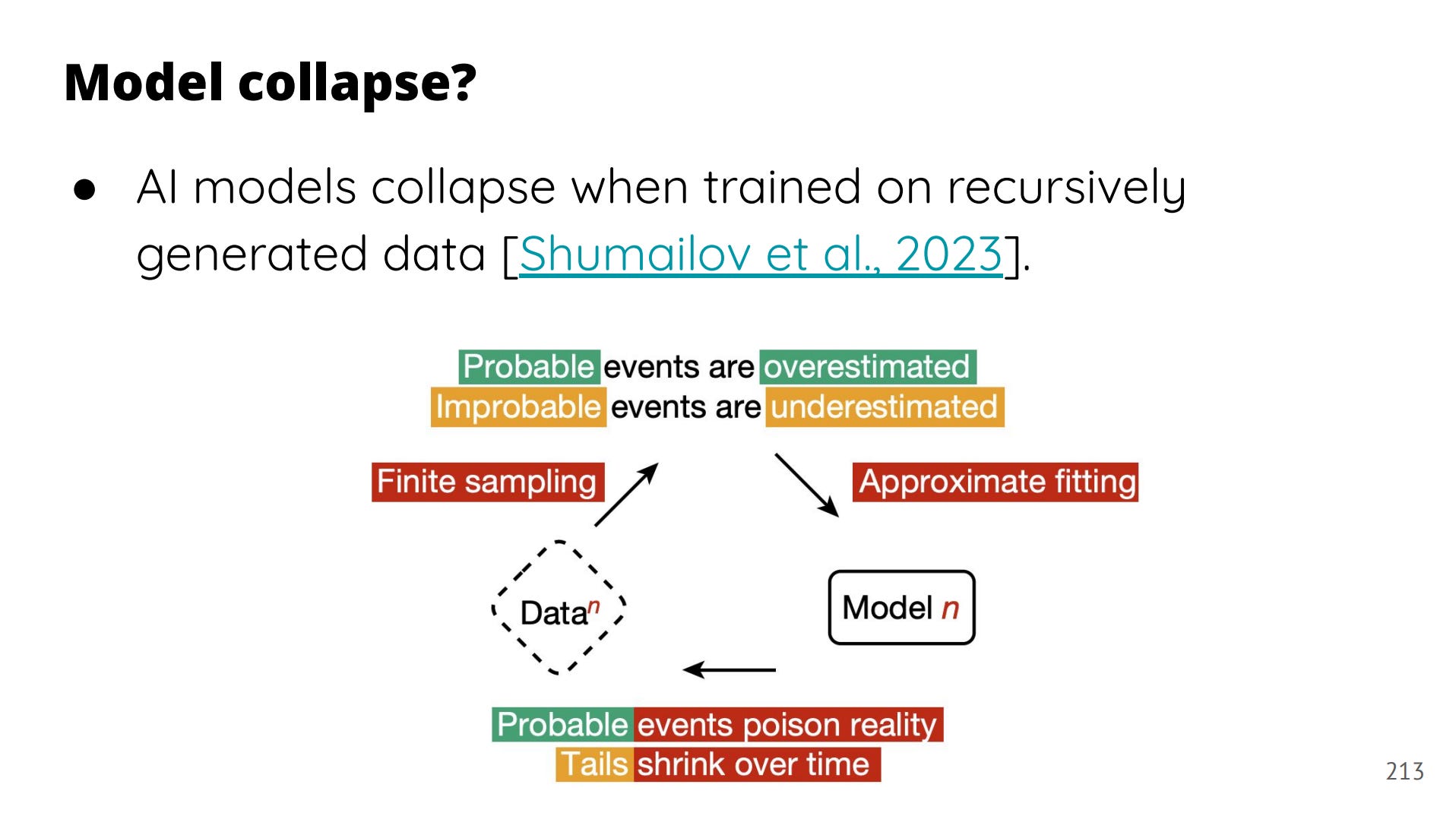
But caution is warranted: synthetic pretraining can lead to collapse if models are trained on recursively generated data. That’s when the model learns one pattern, amplifies it, and becomes unusable.
Still, the tutorial offers hope: models can self-instruct, self-refine, and self-reward. Diversity, again, is key. Incorporating human feedback helps too.
Applications in reasoning, tools, and agents
Use cases discussed include:
Reasoning tasks
Code generation
Tool use and agent orchestration
Multilingual and multimodal data
One exciting area: fine-tuning models to reason which tool to choose in a given task. That’s still hard for models, and synthetic data can provide the necessary training signal.
Limitations and legal questions
Synthetic data struggles with long-tail phenomena. Real-world data is naturally messy and diverse. Synthetic data, by contrast, is curated—and often reflects the biases of the teacher model. Artifacts get propagated.
And then there’s the elephant in the room: licensing. Not all teacher models allow their outputs to be used for training other models. OpenAI, Anthropic, and Gemini explicitly prohibit it. DeepSeek allows it. But what counts as “competing” is vague—and many still use restricted models to generate synthetic datasets anyway. Yet, it is extremely hard to enforce the rules.

Now let us talk about how these knowledge can be used in applied ai and what real use case that we face on a daily basis can benefit from syntactic datasets.
Practical Applications of Synthetic Datasets in Real‑World Use Cases
This section will give you examples of real world use cases that could benefit from synthetic datasets. These examples were not a part of the tutorial and are compiled based on my professional experience.

1. New Coder Onboarding Copilot
Problem: New hired coders waste hours reading READMEs, modules, and commit logs to figure out the key logic of the code
Solution: Pull your repo’s READMEs, top modules, wikis, sharepoint documentation, UML diagrams, recent commit messages etc. Feed this information to an LLM to describe the input in natural language. Once everything is in a natural language, the LLM should generate N questions that could be answered by those paragraphs. Store the resulting {question, summary, file_ID} triples in a vector store alongside the code. When a developer asks, “Where do we validate JWTs?” or “Why did we switch to async I/O?”, the retriever surfaces the matching summary, links to the source file, and the LLM expands on the answer. Regenerate the synthetic Q&A. You can connect the onboarding copilot to Github Copilot throw an MCP so that the developers had informed answers when working with the code.
Technique used: Code‑to‑summary transformation plus back‑translation‑style question generation.
2. Agentic AI Orchestration
Problem: LLM‑driven apps often don’t know which internal tool or API to use. A single question might need a SharePoint search, a proprietary REST call, a follow‑up request to the user, or even a hand‑off to a human but a off-the-shelf models can’t pick reliably.