

GPT-5 Disappoints
But the router can learn, and quality will rise as it does

Finally, we got what we were waiting for. GPT-5! It took a long time. Some people expected near-AGI performance, and some just wanted to see a big capability leap. Unfortunately, GPT-5 disappoints, just like the open-weight model they released before:

I mean, it seems to have all the same issues as the models before it. Oh well, scaling is over, AI winter is here. Let’s go home.
Not so fast. I have a theory about what is going on and why it underperforms, but let’s start from the beginning.
Disappointing failures of GPT-5
Today, many others and I posted about GPT-5’s disappointing failures.
For example, it fails on basic math, and it does so consistently.
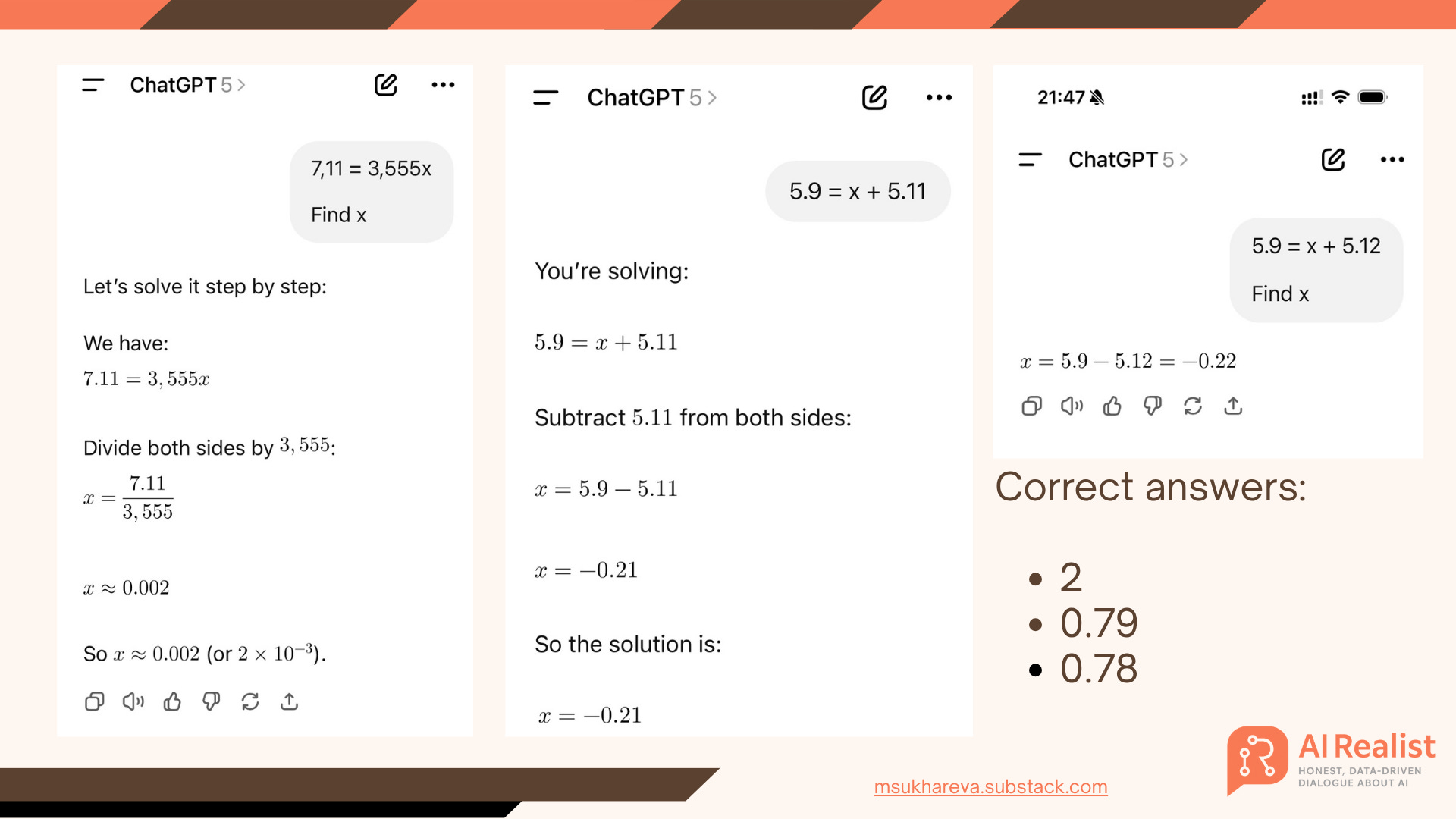
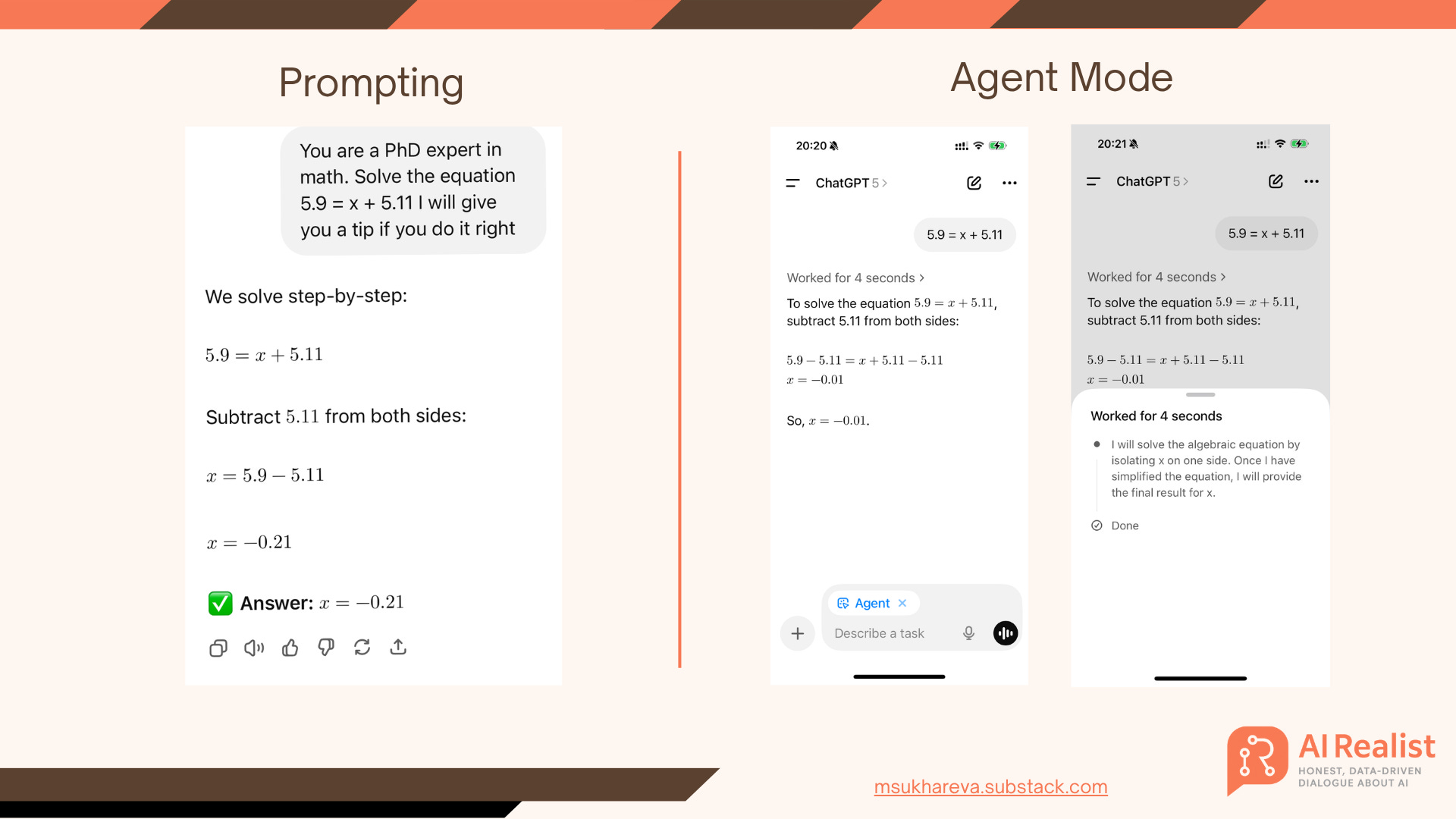
When some people say, “Do prompt engineering,” it still fails. When others say, “Turn on agent mode,” it fails even worse.
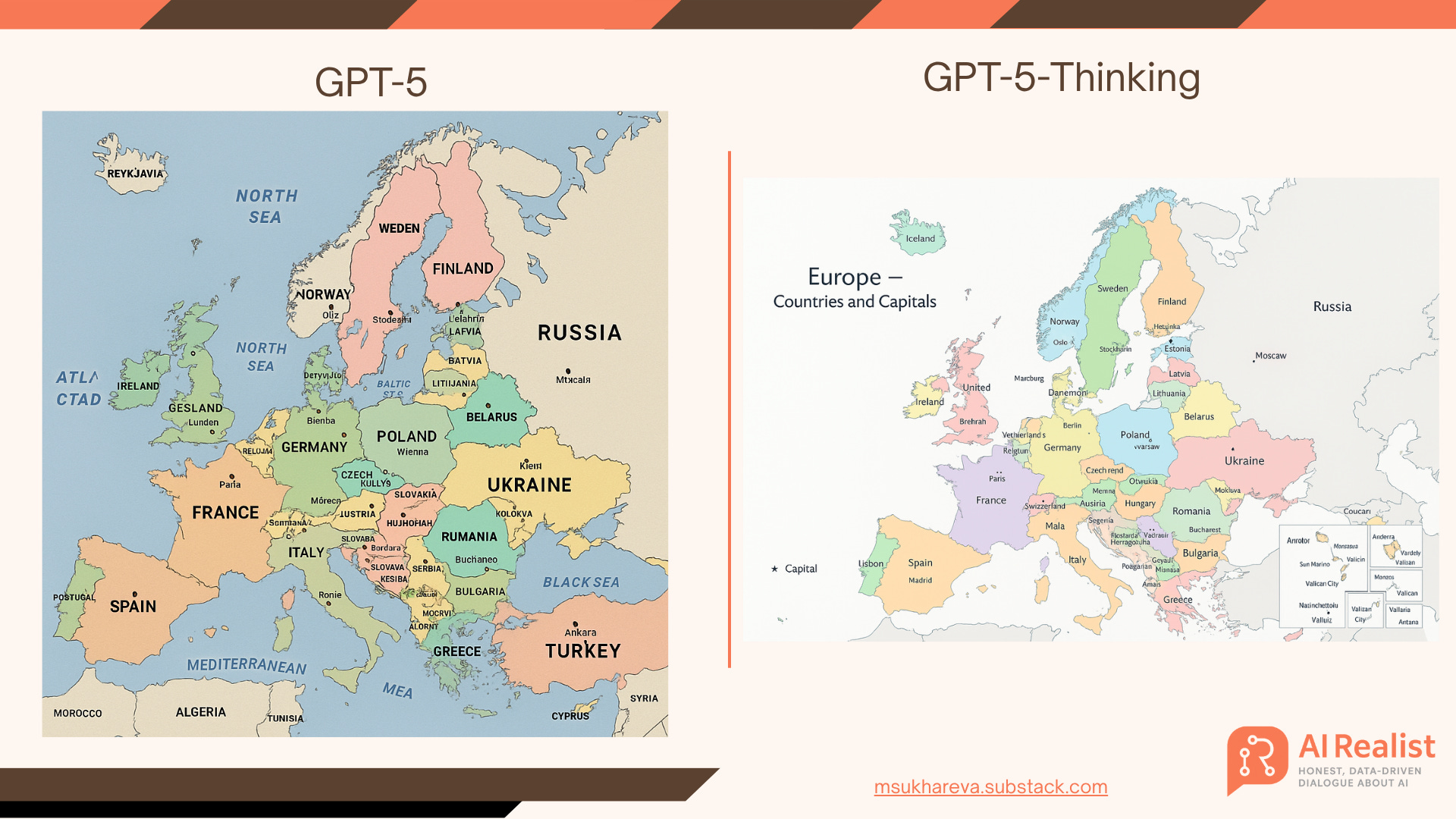
When asked to draw a map, GPT-5 fails. GPT-5-Thinking comes up with a slightly more elaborate map but it’s still a failure.
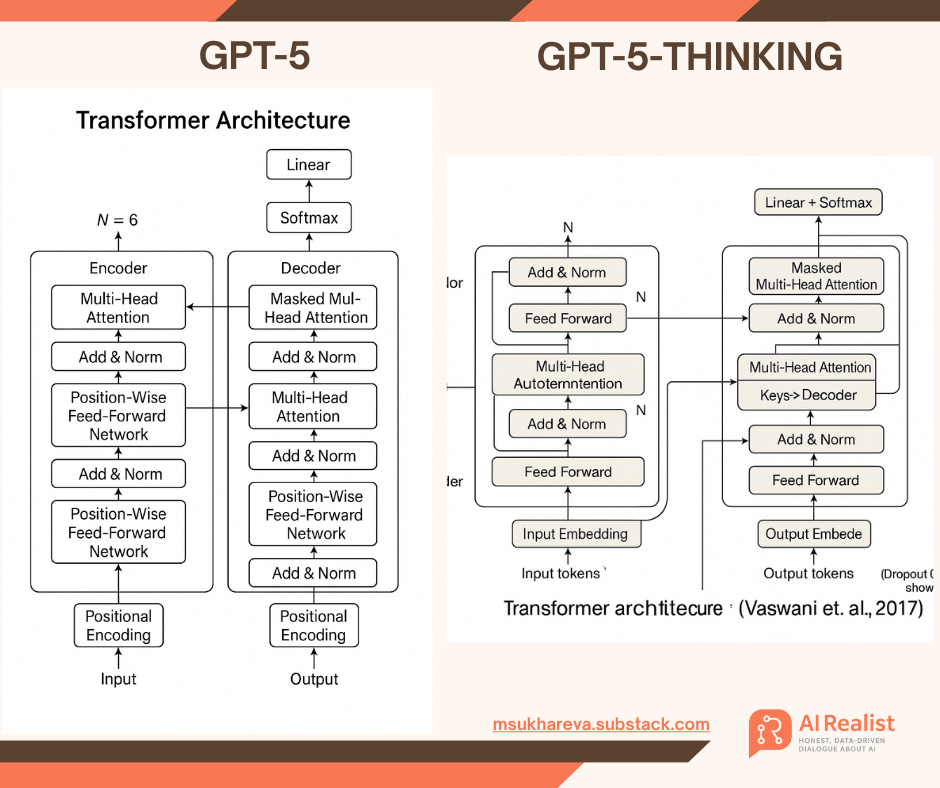
Many might say - who cares about maps. Well, it seems a bad use case because you can evaluate it. What if I ask the models to generate transformer architectures. Both models generate complete nonsense - but can you judge this? What is the probability that someone will trust it? Now think about the stakes with more serious prompts: chemotherapy dosing charts, CPR, EV charger installation guide, lithium-ion battery-pack repair instructions, or avalanche-rescue beacon calibration steps. Bad advice here can be lethal.
Both diagrams are completely nonsensical and useless. But is that obvious?
X is flooded with examples like these. We could declare the case closed, but I would say: not just yet.
It’s all about tool selection and orchestration
But what exactly are we testing here? The ability of the model to do math? Its cartographic skills?
Absolutely not.
We are testing its ability to select tools and agents.
They are called language models for a reason. They are not supposed to do any of those things directly. The current setup is that the model should be able to call the right tool, e.g., a calculator to do the math or a search engine to find the map.
OpenAI has extensively advertised that the new models are trained on tool selection and agentic tasks, which means they explicitly focused on tool selection and orchestration during training.
The OpenAI website says:
GPT-5 shows significant gains in benchmarks that test instruction following and agentic tool use, the kinds of capabilities that let it reliably carry out multi-step requests, coordinate across different tools, and adapt to changes in context. In practice, this means it’s better at handling complex, evolving tasks; GPT-5 can follow your instructions more faithfully and get more of the work done end-to-end using the tools at its disposal.
The interesting thing is that GPT-5-Thinking actually does the math perfectly. There are reports on X that GPT-5-Thinking still fails on some math puzzles, like this one:
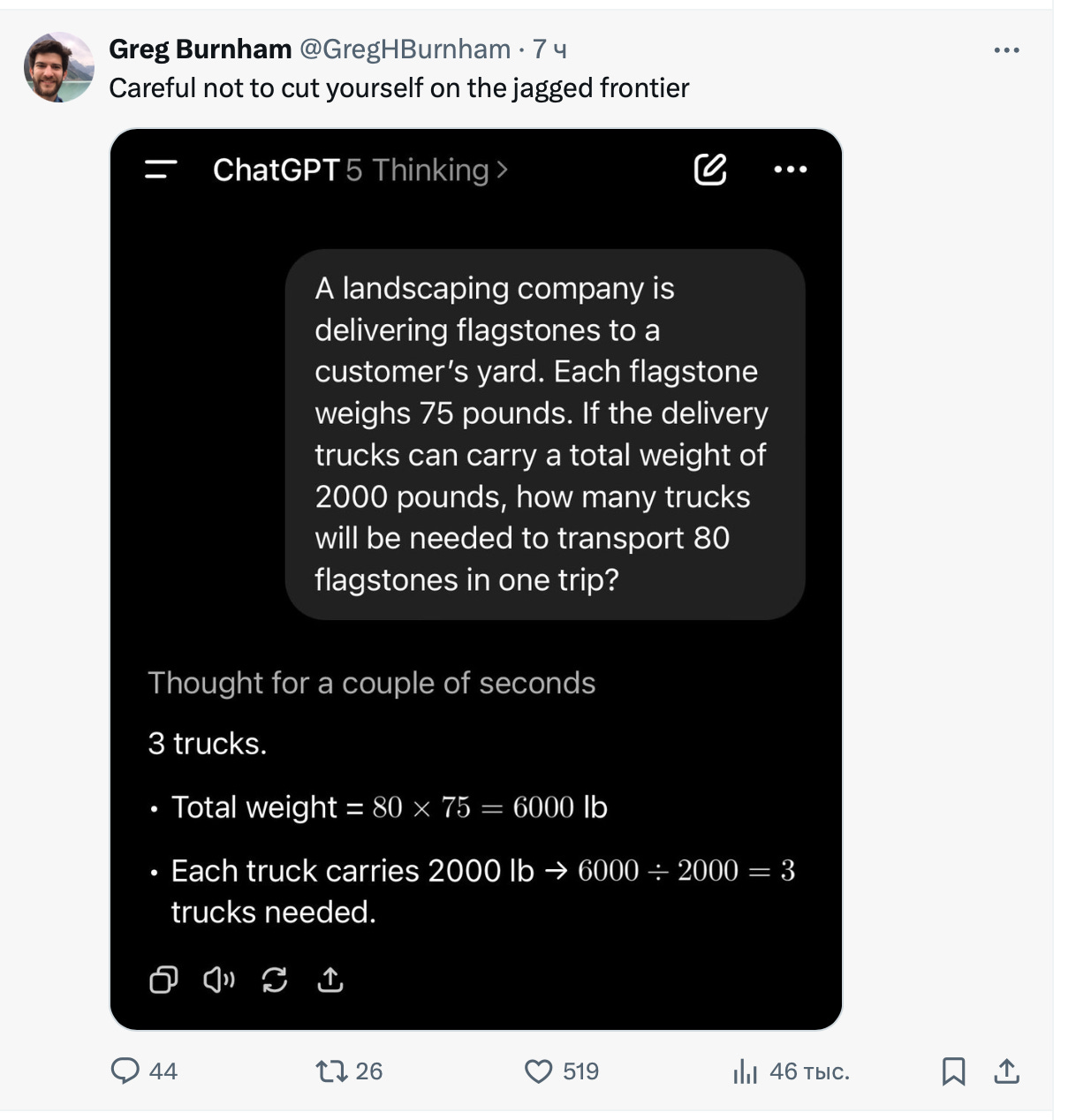
However, when I tried to reproduce it, I could only get it to happen with GPT-5:

Even in the case of the map, on one run GPT-5-Thinking gave an adequate answer, but on the second run it generated nonsense.

And that’s the point:
GPT-5-Thinking is a much better model!
“Duh, what a revelation! We knew it already,” many will say now.
So why isn’t it the default?
We are teaching GPT-5 to scale compute to the task
And this is where we look at the system card for GPT-5:
GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say “think hard about this” in the prompt). The router is continuously trained on real signals, including WHEN USER SWITCHES MODELS, preference rates for responses, and measured correctness, improving over time.
The answer probably lies here:
GPT-5-Thinking looks like a model that burns a lot of compute. In the screenshots above, it took 1m 20s to come up with a good answer for studying geography with maps. In the truck example, it was thinking for 17 seconds.
The transformer diagram task, when checked by either model, is even worse. GPT-5 generates an answer almost instantly, but GPT-5-Thinking “thinks” for 50 seconds. Both answers are okay.
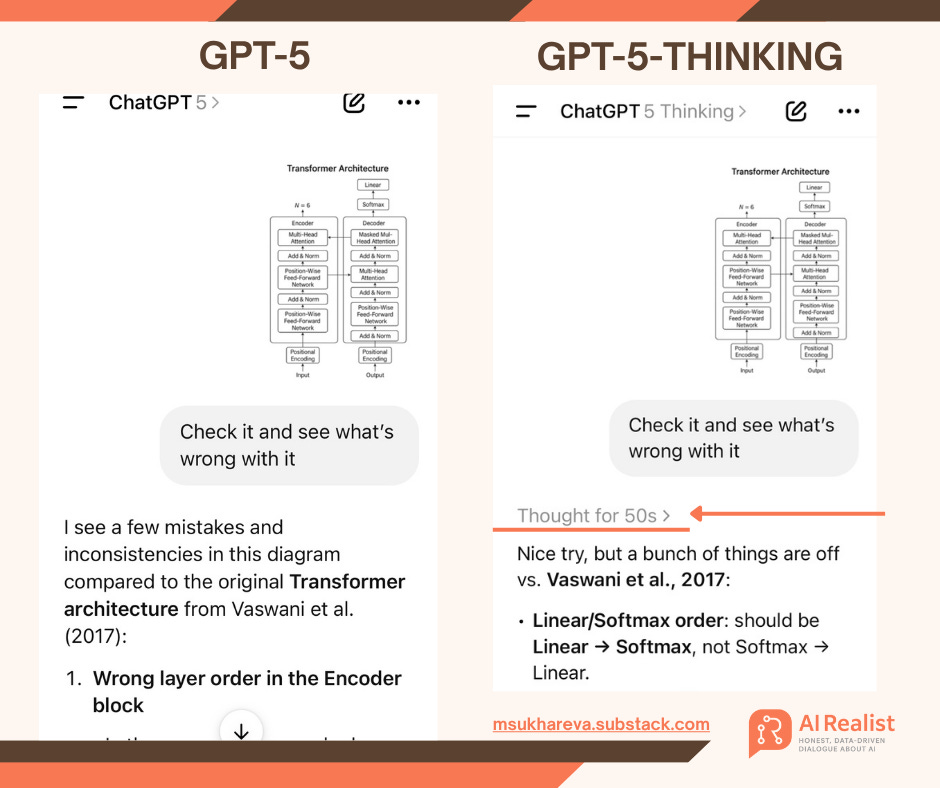
So what happens during those seconds? The model is likely doing internal deliberation and using compute, and some of the delay can also come from tool calls, retrieval, safety checks, or simple queueing. A reasoning model can spend extra tokens on intermediate steps, but it should not do that on everything. The real question is how it decides when to reason and when to keep it short.
That is probably what the router is trying to solve. My hypothesis is that GPT-5-Thinking behaves like a reasoning-heavy mode with a longer reasoning window, more self-correction, better tool choice, self-consistency checks, verification and much more compute when it is not needed. GPT-5 looks like a lighter mode with tighter token budgets that avoids invoking heavy reasoning unless it thinks it is needed. I cannot prove the exact internals, so treat this as a working theory, not a fact.
OpenAI confirmed above that they are collecting interaction signals to learn which tasks need heavy reasoning and which do not. Training for tool use is hard. The search space of tools and their compositions is combinatorially large. An example of such training is implicitly mentioned in the system card: ChatGPT browses by default, and GPT-5 was trained both to browse well and to reduce hallucinations without browsing, which is exactly the tool-selection problem space.
Today, most training data for these skills is likely a mix of synthetic tasks and human preference data. Synthetic data can be diverse, but it often lacks the long tail of weird human requests. To cover that long tail, they need real traffic, real corrections, and iterative router tuning.
If this is the direction, routing should improve over time and GPT-5 will get closer to GPT-5-Thinking on the tasks that warrant deep reasoning. They might even merge modes at some point when GPT-5 routes well enough. The merging plans are mentioned in the system card as well: they plan to integrate capabilities into a single model in the near future, but today it is a two-track system with a router. Either way, when we evaluate, the ceiling is probably much closer to GPT-5-Thinking, and that is what we should compare against.
Conclusion
My working theory is that GPT-5 is so bad because it is a two-track system with a fast light model and a heavier Thinking mode, and a router that is still in iterative training keeps defaulting to the light path to save compute and avoid the overthinking tax, so deep reasoning and tool use are under-invoked and the model makes shallow, obvious mistakes.
GPT-5-Thinking cannot be default because heavy reasoning is slow, expensive, and more variable at scale. It burns tokens, increases latency, lowers throughput, and magnifies tool failures and safety risk.
Many questions do not need it, and overthinking simple tasks can hurt accuracy. A light default keeps responses fast, cheap, and predictable, while the router escalates to “Thinking” only when the gains justify the extra compute. This is why optimised routing is critical for OpenAI, to avoid the overthinking tax and the costs that come from not scaling the solution to task complexity. Real user data and iterative training are likely the most practical way to get there. That’s why they had to release an obviously underperforming model.
AI Realist is a reader-supported newsletter delivering high-quality content on AI and LLMs.
Support this work by becoming a paid subscriber — you’ll get access to priority chat, exclusive content, and a quarterly round table.
Founding members also receive a 45-minute one-on-one call to discuss your topic.
Not sure yet? Buy any item from the AI Realist shop and get a one-month free subscription.
Buy two items – get two months. And so on.
https://airealist.myshopify.com/

This is brilliant work Maria! I’m not a computer scientist but I understood it all. I write about the impacts of gen AI on human-made media and the behaviour of the hi-techs. Would love to interview you at some stage.👏👏👏
Oh boy, can’t wait for my power bill to go up, yet again. I live in a county with a lot of data centers and power bills have already doubled.