

The mystery of em‑dashes: part two with quantitative evidence

A couple of weeks ago I made an assumption: the rise of em‑dashes in AI‑generated text happened because model providers started scanning older, pre‑Kindle books.
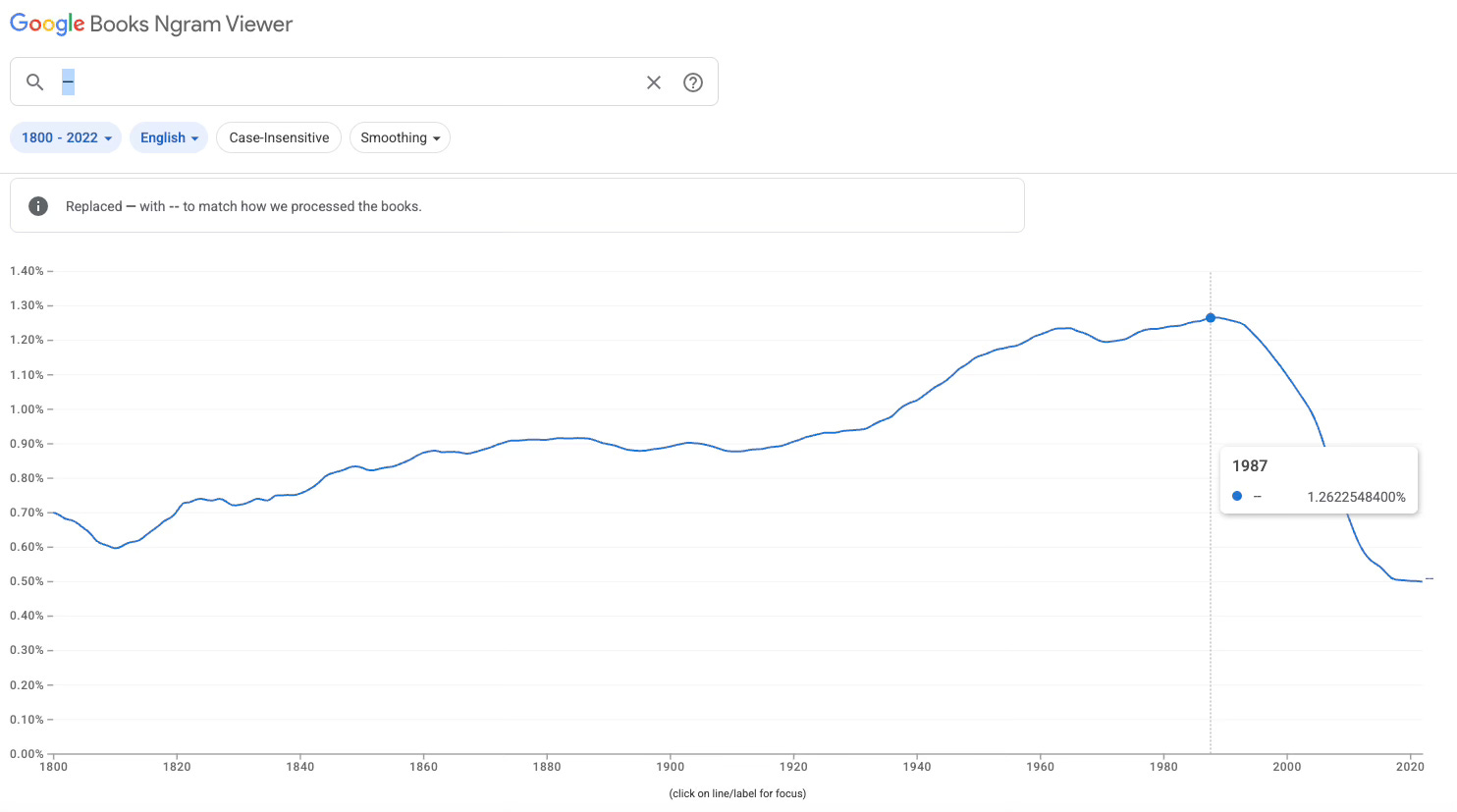
Google Ngrams shows that em‑dash usage peaks before large‑scale digitalisation, so if those books suddenly enter the training mix, the punctuation habits of the past hitch a ride into the present.
A few month ago Ilya Suskever said:
“We have to deal with the data that we have. There's only one internet.”
So that is not surprising that LLM providers started digitizing older books to acquire new data. Anthropic has reportedly scanned and ruined millions of books.
An unexpected effect of this is that models starts overusing em-dashes. I assume that it has a simple technical reason. When a model writes it predicts token by token and its loss is a running sum over those tokens. Fewer tokens mean a slightly lower loss, and reinforcement‑learning fine‑tuning pushes in the same direction by penalizing for brevity. In UTF‑8 tokenisation one em‑dash (—) is a single token, whereas the sequence “, and” is three. In other words, an em‑dash is a bargain.
That led me to two testable hypotheses:
H1: Newer models are trained on different data with more em‑dashes. If true, older models should use markedly fewer dashes.
H2: Em‑dashes save tokens. Removing the dash should make a sentence longer in token terms.
If you enjoyed this post, follow me here on Substack and if you’d like to enable more such experiments, consider becoming a paid subscriber.
What I did
I generated 150 random story prompts.
I fed them to three models: the older GPT‑3.5‑turbo, and the newer GPT‑4o and GPT‑4.1. Each model generated a story for the prompt. I did not limit the length of the stories. During generation - GPT-4.1 was occasionally failing and it generated only 130 stories. I suspect it is due to the toxicity filter, probably at some reason it evaluated what was generated as toxic and threw an error. It has been known to happen before. GPT-4o and GPT-3.5-turbo failed to generate one story each.

Table 1: Data overview and Paraphrases For H1 I simply counted the dashes each model produced.
For H2 I pulled every dash‑containing sentence, asked the same model to re‑write it without the dash while changing as little as possible, and kept up to five variants that differed by no more than five words (punctuation included). Then I compared token counts using each model’s corresponding tokenizer.
One of the unexpected challenges here was that paraphrases would simply include em-dashes else where, where they do not belong. I decided to filter out all the paraphrases with em-dashes.

What came out
Both hypotheses held up.
H1: The drastic increase in em-dash usage for newer models
To confirm H1, we need to prove that the older model generated less em-dashes. The increases of em-dashes is dramatic. Later models showed 10-fold increase. We can now speculate that the reason for this is the digitalization of older books.

Even more interesting - every single story generated by the later models contained em-dashes while GPT-3.5-Turbo did manage to generate story without them.

While GPT-3.5 was not overusing em-dashes, the average em-dash count per story was around 10. The GPT-4.1 was using em-dashes at every possibility with the count of over 10 em-dashes per story

H2: All the models exhibit token increase when forced to paraphrase without em-dashes
To test the second hypothesis, I took the following steps:
Extracted sentences
We gathered every sentence that contained an em-dash.Prompted the model
Each sentence was fed to the model with instructions to paraphrase it without using an em-dash, while making the fewest possible changes.Applied a strict filter
To keep the model from becoming too creative, we rejected any paraphrase that altered more than four words.
I discovered that GPT-4o and GPT-4.1 often struggle to rephrase sentences without em-dashes; many paraphrases simply inserted a new em-dash elsewhere. These outputs were discarded. To offset the losses from this filtering, I generated two paraphrases per sentence. If the model could not meet the word-change limit and avoid using an em-dash, that sentence was excluded from the analysis.

Already for the older model, we observed a clear token increase of 1.74% for paraphrased sentences.
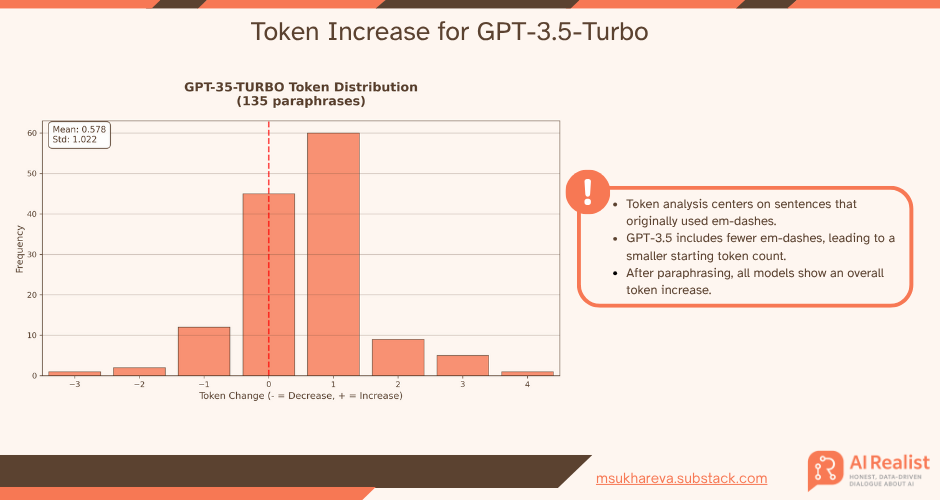
The largest token increase was for GPT-4o. It is as large as 2.23% which is not little considering that the examples were filtered to ensure that only the em-dash part was changed.
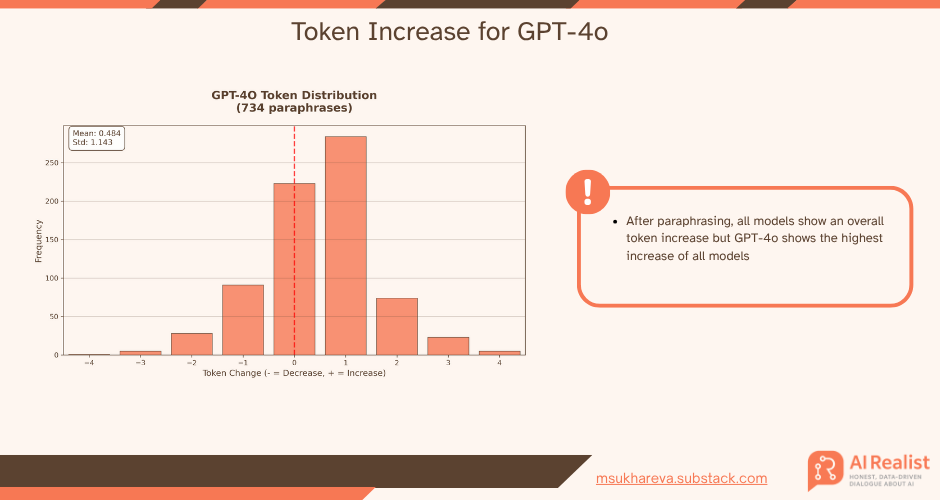
Finally, GPT-4.1 has also shown token increase for the paraphrasing, however, the increase is the smallest among all three models.

Explanation: why it happens
I have two hypothetical explanations why the model so eagerly picked up on em-dashes and tends to include them everywhere, where they belong or not.
Reason 1: the brevity bias of the reinforcement learning
OpenAI’s RLHF stage optimises a reward that balances a scalar human‑ or rule‑based score with a per‑token KL‑divergence penalty against the supervised baseline (typically via PPO). Because that KL term is summed token‑by‑token, longer completions cause a proportionally larger penalty:
we add a per-token KL penalty from the SFT model at each token to mitigate over-optimisation
The policy therefore earns higher adjusted reward for equally good, but shorter, answers, that steers the generation toward brevity and, also, cutting token usage and compute. The official explanation why it is done is that if the brevity penalty is removed, reward models often swing in the opposite direction, that is over‑valuing length and producing verbose or even looping output.
Reason 2: How the loss actually looks
During training, GPT models minimise token‑level cross‑entropy. Written out, the objective for a single example is:
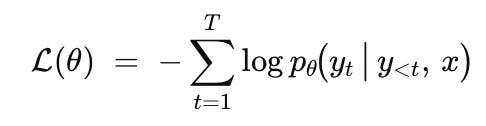
where θ are the model parameters, T is the number of tokens in the target sequence, yt is the gold standard token at position t, and x is the (optional) conditioning prompt or context. Because the loss is an ordinary sum over T terms, a five‑token sentence contributes five negative log‑probability penalties, whereas an eight‑token sentence contributes eight. All else equal, shorter sequences push the raw loss down.
Simply speaking, if we calculate the loss for a sequence of two words and three words


The loss for two tokens can be slightly smaller just because it is a sum.
Take the line:
The—cat—leaps.
GPT‑4’s tokenizer might yield four tokens: The, —, cat, —, leaps. The training loss is the sum of four log‑probabilities.
Now force the same meaning without dashes:
The , and cat , and leaps .
That expands to eight tokens (The, ,, and, cat, ,, and, leaps, .). Even if the per‑token probabilities stay unchanged, the additive penalty roughly doubles, pushing the optimiser, across billions of updates, toward the cheaper, dash‑laden phrasing.
Github Repository
If you want to reproduce the experiment, see the exact prompts or regenerate the visuals, you can use my GitHub repo:
https://github.com/ktoetotam/mystery-em-dash/tree/main
Why it matters
If every new model trains on the output of the previous generation, stylistic tics like the em‑dash can lead to what researchers call model collapse. More and more texts are being edited or generated with a LLM. If this continues, very soon internet will be filled with em-dashes. The next model will be trained on this input. When each new model trains on the outputs of earlier models instead of fresh, human‑authored text, they amplify the weirdness of the predecessors .e.g., high‑probability clichés, favoured punctuation, safe canned phrases. Rare patterns fade. Over successive generations of models the distribution narrows, stylistic diversity shrinks, and the model becomes repetitive. To avoid that, providers will need to:
Detect and filter data saturated with ChatGPT‑isms.
Actively optimise reinforcement learning for stylistic diversity, not just brevity.
These results are a reminder that models aren’t reasoning or thinking, they are cursed with all the problems that come with machine learning.
Wow. Model collapse. In my head it sounds awfully similar to bubbles bursting.
An em dash isn't just an alternative to ", and" though.