


Let me channel my inner
and say - I told you so.A couple months ago I posted my predictions on GPT-5. It think it is time to take a look back and see if they measured up.
Prediction one: ensemble of models
It won’t be a new architecture or algorithm. It will be an ensemble of models: text, coding, image generation, maybe even video. The user will perceive it as one model because the orchestration will happen in the background. That’s actually ok, not a bad solution.
Confirmed: the system card for GPT-5 explicitly states that it’s an ensemble of models.
Furthermore, the disastrously disappointing launch of GPT-5—where the model appeared to perform worse than its predecessors—prompted OpenAI to officially post this, hinting that there may be far more models involved than the system card suggests.
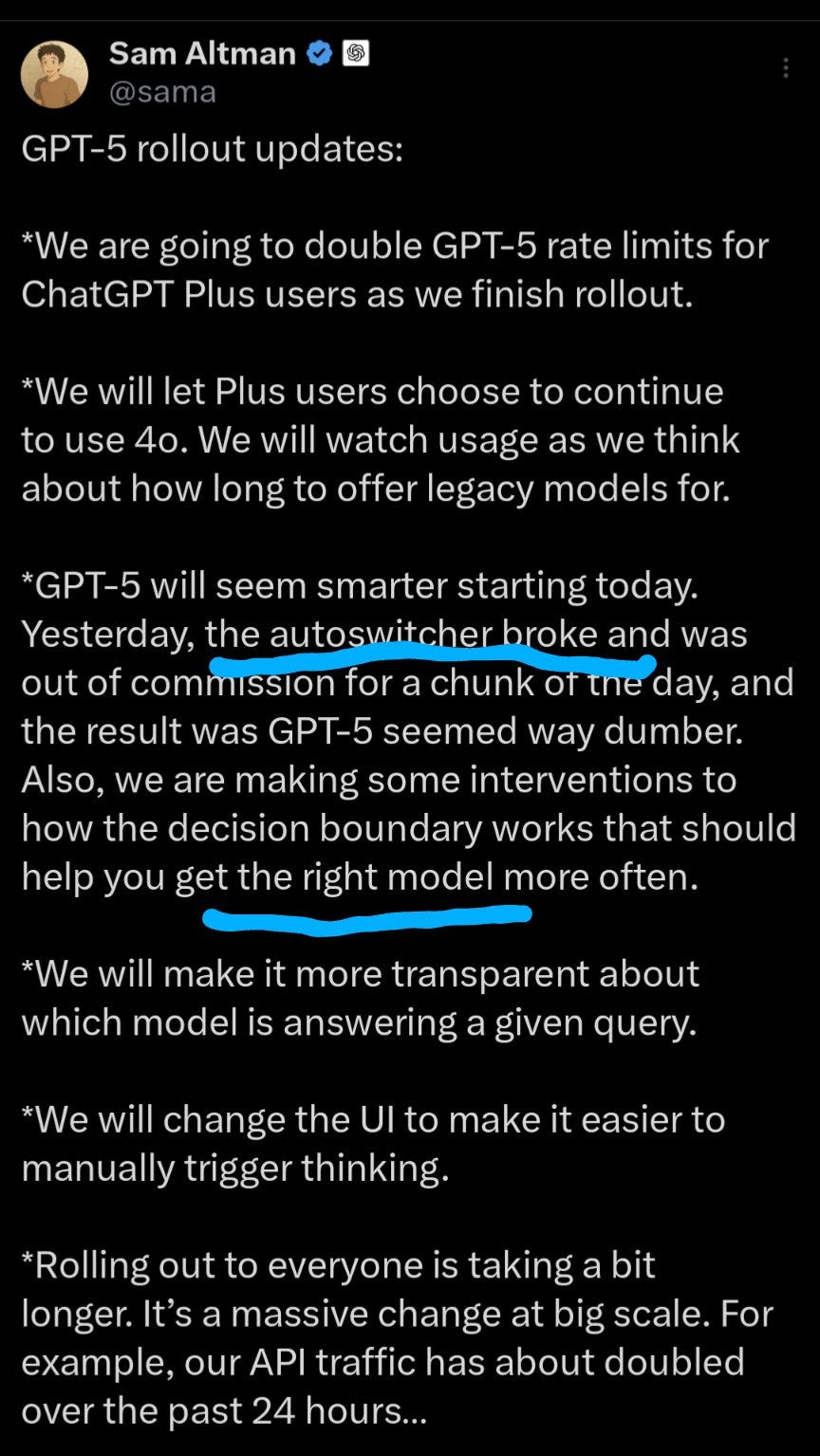
Prediction 2: Focus on tool use and agents
It will be heavily optimized for tool use and marketed as agentic AI or something like that. It will likely finally figure out it needs to write Python code to count the “r” in 🍓. It might still struggle with g’s though.
Confirmed. Its routing architecture, and the optimization of that routing based on task complexity and tool requirements, is a clear sign that the model was heavily trained for tool orchestration. Indeed, it manages to pick up on some tools and invoke them correctly, but at the same time it often fails to choose the right ones. It calls image generation when it shouldn’t, struggles to figure out the appropriate use of calculators, and fails on many tasks.
The focus on tool orchestration has also hurt its ability to generate text [source]. Since tool orchestration is an extremely difficult challenge, it’s likely that OpenAI is currently collecting data and optimizing its router. More here:

Prediction 3: Beat benchmarks, disappoint users.
It will beat a bunch of public benchmarks. People will scratch their heads wondering how, because it won’t feel that different.
100% confirmed: GPT-5 scored 100% on AIME, yet fails on basic math (see the post linked above). While it surpassed many other benchmarks, the launch has still been met with massive disappointment from users. Many report barely noticing any improvement, and some are even demanding the return of the old models:

Prediction 4: Better RAG setup, search, internal data and multi-source RAG
It will offer much better support for RAG setups. Optimized for search, internal data, and especially multi-source RAG. They’ll start targeting seamless integration with knowledge sources like Google Drive, SharePoint, etc.
Confirmed. The system card explicitly mentions integration with search and the orchestration of search tools.
“While ChatGPT has browsing enabled by default, many API queries do not use browsing tools. Thus, we focused both on training our models to browse effectively for up-to-date information, and on reducing hallucinations when the models are relying on their own internal knowledge.” [source]
It is also targeting multiple sources, particularly for business solutions:
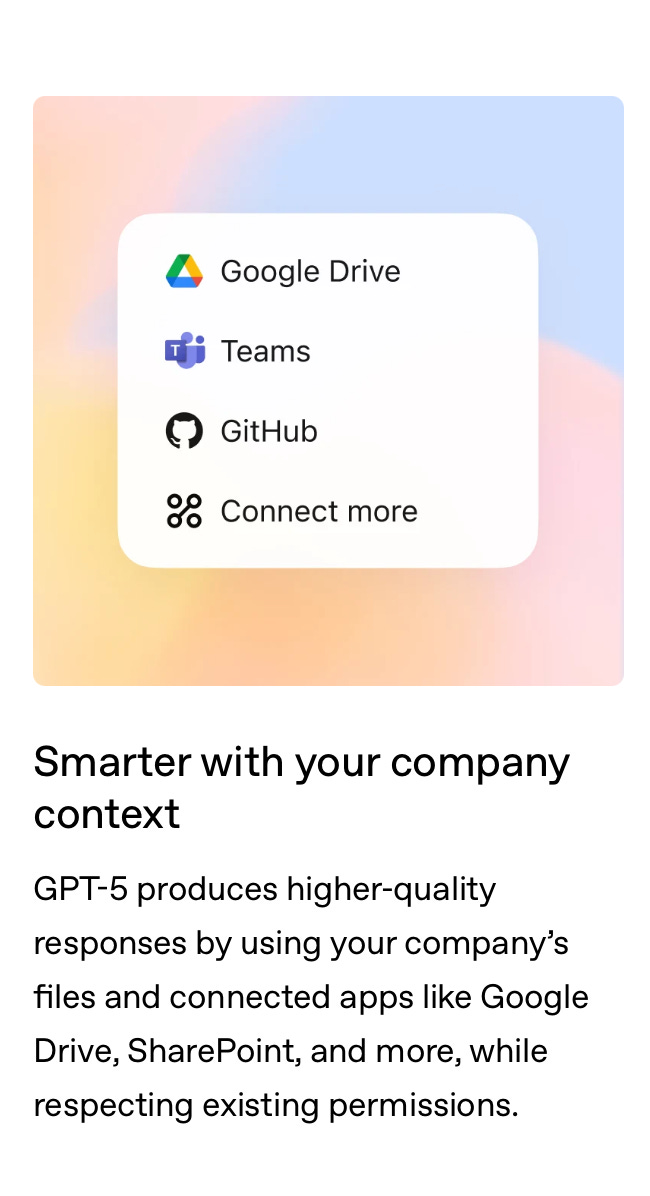
Prediction 5: Advertisements
It will start selling you stuff. Subtle commercial offers and shopping assistance will show up.
Not confirmed. At least not yet.
Prediction 6: Multimodality Boost
The biggest step forward will be in multimodality: image, video, audio. Text and code generation won’t feel like a big leap.
Wrong. That’s where I missed the mark. I was too optimistic. The image generation is still routed to the old DALL·E model, producing hilariously bad images like this one:

There is no video model integrated with GPT-5 - no Sora update or anything comparable to Grok Imagine. The only substantial improvement appears to be in the audio model, which was included in the announcement. Code generation seems to have improved the most, while text generation has been widely reported to have gotten worse.
Prediction 7: The great disappointment
For many, it will feel like a letdown. Expect headlines like “AI Winter is here,” “AI progress has stalled,” or “AI has plateaued.” Confirmed. Even the most dedicated AI hypers show disappointment.
Confirmed. This is one of the biggest disappointments in AI history. It’s not even that the model is bad, it’s that the unrealistic expectations, fueled by outright lies about what transformers can achieve, inevitably led to a loss of trust and frustration among those who had high hopes for this release.
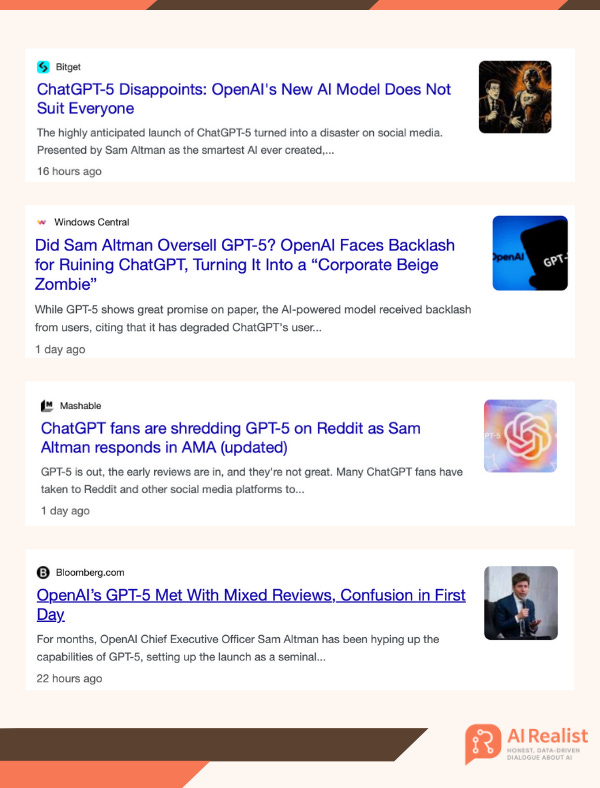
Prediction 8: They will boast about a model with a gazillion parameters.
They’ll advertise it as a gazillion-parameter model. The improvement won’t be gazillion-fold, so expect debates on whether scaling still works.
Wrong. They didn’t mention parameters at all. That could mean it’s either not much larger, or, most likely, that marketing a “gazillion-parameter” model is now seen as bad strategy, especially since Chinese teams keep releasing strong small models. It could also be to avoid triggering environmental activists and others concerned about AI’s energy consumption.
My guess is that it’s actually a massive model with huge energy demands. Here, I’m primarily referring to GPT-5-Thinking. As I argued in the newsletter linked above, they likely had to release an underperforming router, branded as GPT-5, as the flagship model, in order to save costs and optimize routing through user interaction and feedback.
The fact that OpenAI refuses to disclose the energy consumption likely supports this theory:

Prediction 9: Massive context window but poor performance
They’ll claim a massive context window, but it will be mostly unusable - too expensive in tokens and poor at retrieval, especially with the needle-in-a-haystack problem.
Not enough information yet. There’s ongoing confusion about the context window - some report having access to 400k, others to 256k. Anecdotal evidence from developers suggests there’s no massive improvement over Claude. OpenAI’s own evaluations, of course, claim that they outperform every possible benchmark, but we already know those reports can’t be taken at face value.
Prediction 10: China will catch up quickly
Two weeks later, DeepSeek or someone similar will reverse engineer it and shrink it enough to run on a local PC.
It is too early to judge but R2 is probably coming soon and then we will see.
Prediction 11: It will have all the same problems with hallucinations
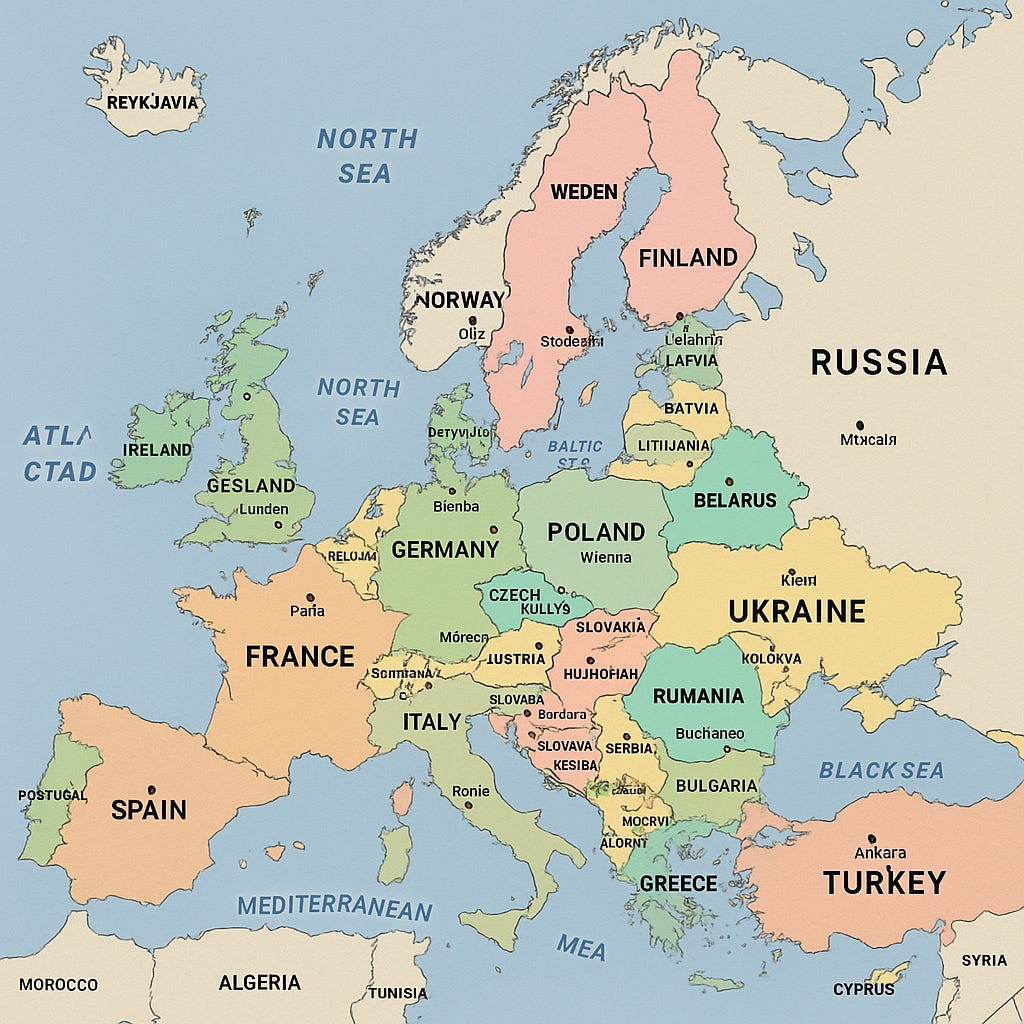
It will still hallucinate, won’t generate good maps, but I believe it will finally manage to count the “r”s in 🍓.
Confirmed. It hallucinates, produces hilarious maps, but manages to count letters, at least most of the time. X is full of examples of such failures.
Prediction 12: Multiple models
There will be GPT-5.5, GPT-5o, GPT-5x, GPT-5.1, GPT-5.123 but they’ll eventually stop shilling the GPT brand. The next hype will be some new buzzword. Maybe AgentX, maybe something even more random. Not clear yet.
Partially confirmed. Even at launch, they released five models, GPT-5, GPT-5-mini, GPT-5-nano, GPT-5-Thinking, and GPT-5-Thinking-mini, and I wouldn’t be surprised if more are coming. The naming is slightly different, but after this disappointment it’s becoming increasingly likely that they won’t be able to generate the same hype for GPT-6 and may need to rebrand.
AI Realist is a reader-supported newsletter delivering high-quality content on AI and LLMs. If you’d like to support this work, consider becoming a paid subscriber.
Not sure yet? Buy any item from the AI Realist shop and get a one-month free subscription.
Buy two items – get two months. And so on.
https://airealist.myshopify.com/

I suspect auto switching is never going to work well. Why not? Because AI has no self-reflection. It doesn't know what it doesn't know.
Therefore, it cannot properly delegate to the correct model that does know.
> There’s ongoing confusion about the context window - some report having access to 400k, others to 256k.
It's 400 k total, 256 output