

Should You Really Write Your Prompt Twice?
Rarely. Only for edge cases.

The paper “Prompt Repetition Improves Non-Reasoning LLMs“ is suddenly going viral.
If you have not read it, here is a very nice summary I generated with NotebookLM of what the paper is about.
The main finding is that sending the same prompt twice improves results for non-reasoning models, as in:
“How many r’s are in strawberry? How many r’s are in strawberry?”
This should work better than:
“How many r’s are in strawberry?”
It might sound silly, but it actually works for non-reasoning models.
I talked about this a month ago in the context of image generation. It works particularly well there. You can read why below:

But let me explain what is happening and why it is not that mind-blowing that sending the prompt twice actually improves the results.
The reason is something called causal masking.

Transformers, by definition, are not recurrent. They process the whole input at once. The original transformers were not designed to generate text. They were created for machine translation. In machine translation, it is completely acceptable to see the full input of the source language during training while generating the translation.
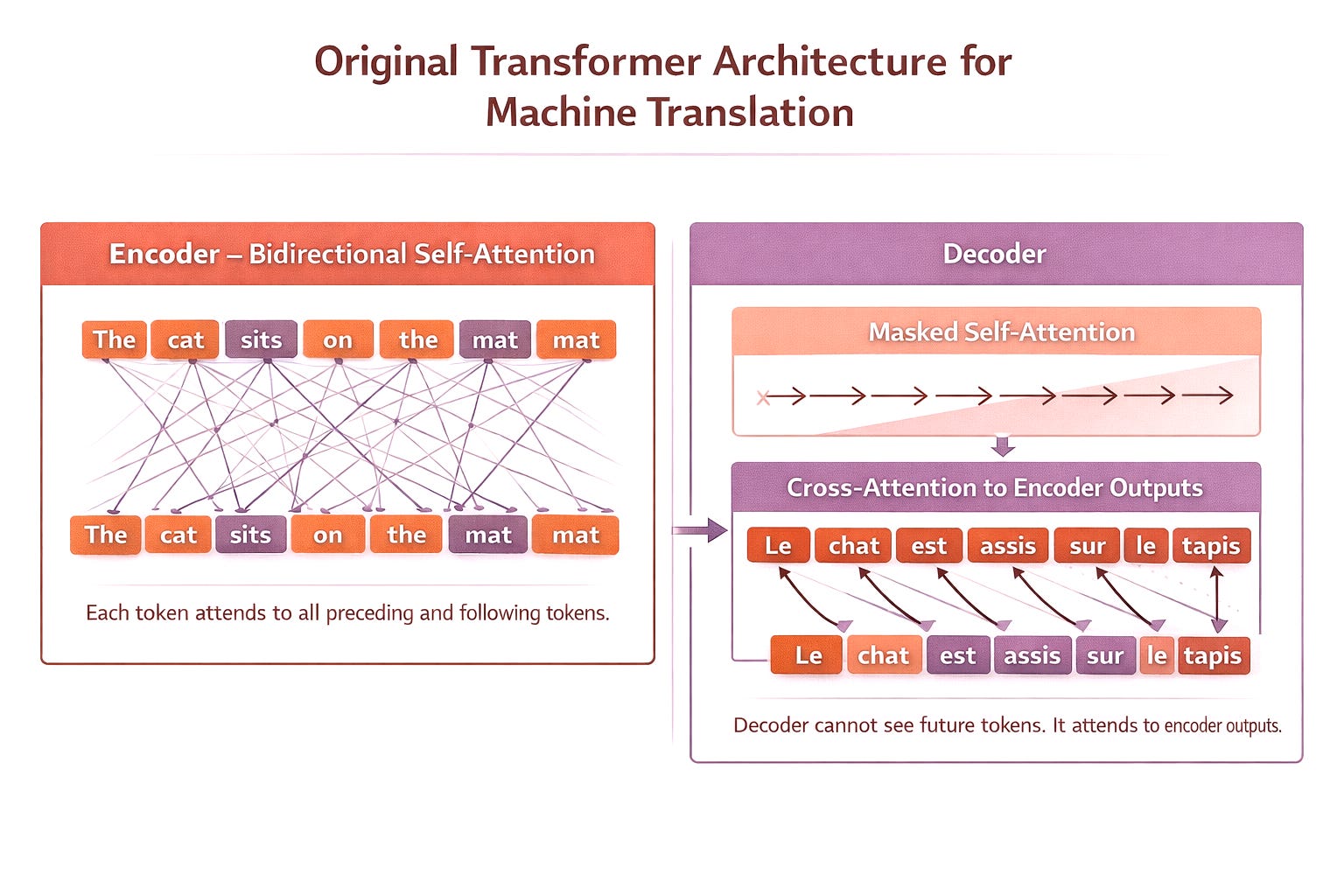
But for simply predicting the next word, this would make no sense. The transformer needs to be artificially prevented from seeing what comes after the current token. Otherwise, it would not learn anything meaningful.That is where causal masking was introduced.
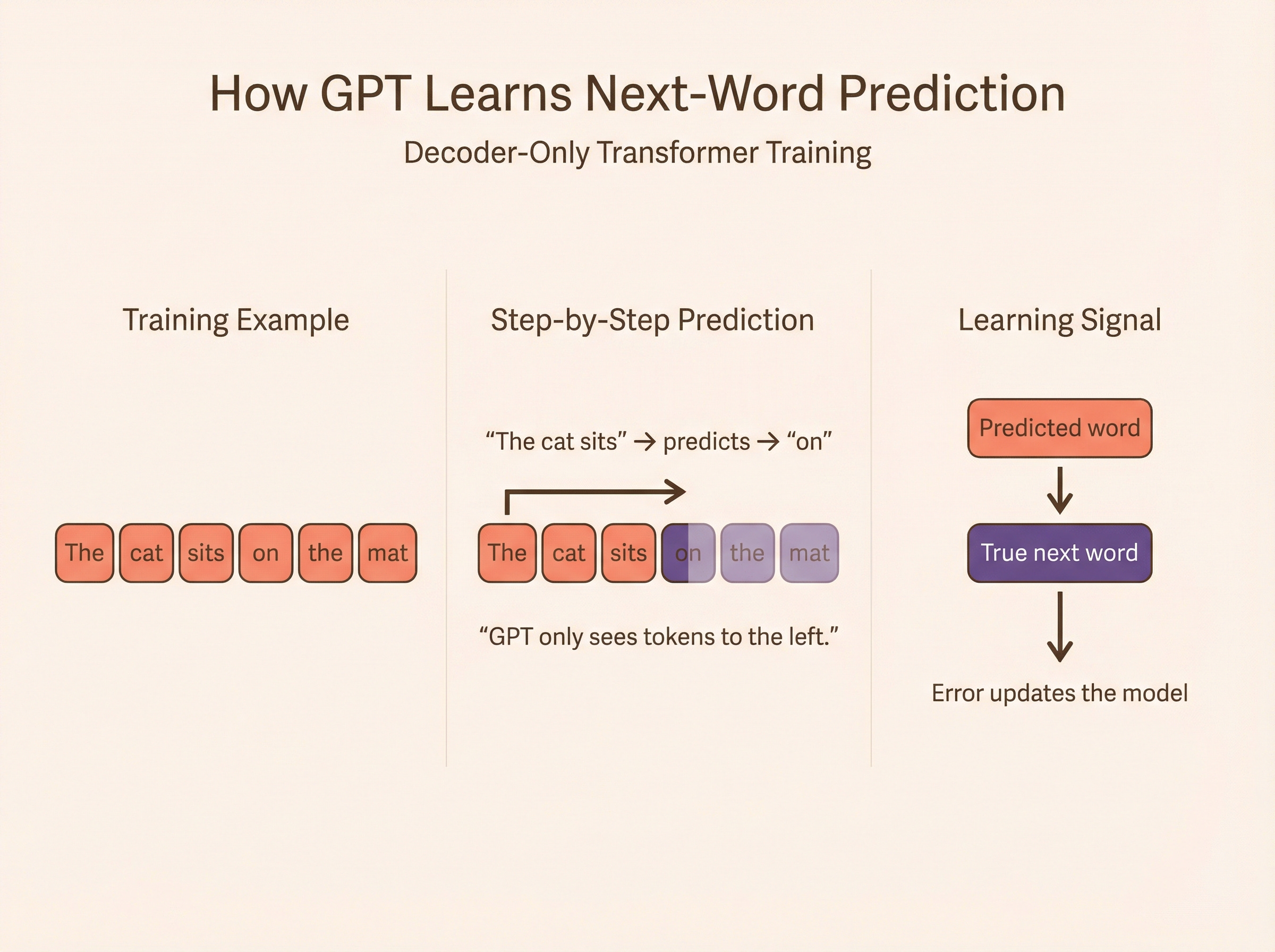
So at every step of generation, a word is encoded only with the preceding context. It only sees the preceding words of the prompt.
For example, the original transformers would produce different encodings for the word “release” in these sentences at the second position:
“This release of the latest Taylor Swift album beat all records.”
“This release refers to a trigger designed to set the process in motion.”
Models like BERT would encode the context that follows the word “release” into its vector representation, and those vectors would be completely different.
In GPT, “release” would only have “This” contributing to its representation, so the encoding at that position would initially be the same in both sentences. The ambiguity is resolved later as more tokens are processed. That is the limitation.
If we repeat the sentence like this:
“This release of the latest Taylor Swift album beat all records. This release of the latest Taylor Swift album beat all records.”
“This release refers to a trigger designed to set the process in motion. This release of the latest Taylor Swift album beat all records.”
In this case, the second occurrence of “release” appears after a full sentence. Therefore, its representation can incorporate the entire preceding context. When the continuation is generated and the vector for this second “release” is processed, the model can attend to the meaning differences encoded in the prior sentence.
Now try to think about why the improvement is observed primarily for non-reasoning models.
Paid subscribers get:
Priority answers to your messages within 48-hours
Access to deep dives on the latest state-of-the-art in AI
Free access to quarterly AI realist training.
Founding members:
A 45-minute one-on-one call with me
High-priority personal chat where I quickly reply to your questions within 24-hour
Support independent research and AI opinions that don’t follow the hype.
