

Why Prompt Engineering Should Not Be Taken Seriously
Why there are no correct and incorrect prompts

As ChatGPT appeared, a lot of so-called AI experts started calling themselves “prompt engineers.” They flooded LinkedIn and Twitter with their “top 10 prompts,” online prompt engineering courses, downloadable PDFs, and other recycled content.
I am guilty myself of making a prompt engineering course as part of my job as Principal Key Expert. But paradoxically, the point of that course was to teach people not to take prompt engineering seriously.
My goal was (and still is) to teach people to use these models in a way that makes them understand their limitations. I believe LLMs can be extremely useful when applied to the right use case.
There is no productivity gain if someone wastes hours searching for the “perfect” prompt for something the model cannot essentially do. And there is nothing meaningful about tips like calling an LLM an “expert,” telling it to “think step by step,” or wrapping your prompt in elaborate templates. All this is just a casino—you hope for a good outcome, but you’re essentially gambling.
I do not argue that a prompt has no impact on the output - on the contrary, it has too much impact. An impact that is inconsistent and difficult to control. It is a useful skill to be able to word your query so that it returns a good answer, but it is equally important to know when to stop tuning that query and to understand that no amount of prompting can ensure consistency.
The article is structured as follows:
Some fun anecdotal evidence and its discussion
A deep dive into peer-reviewed literature to make sense of what is happening
Anecdotal Evidence: “But your prompt is incorrect!“
I recently came across this article:
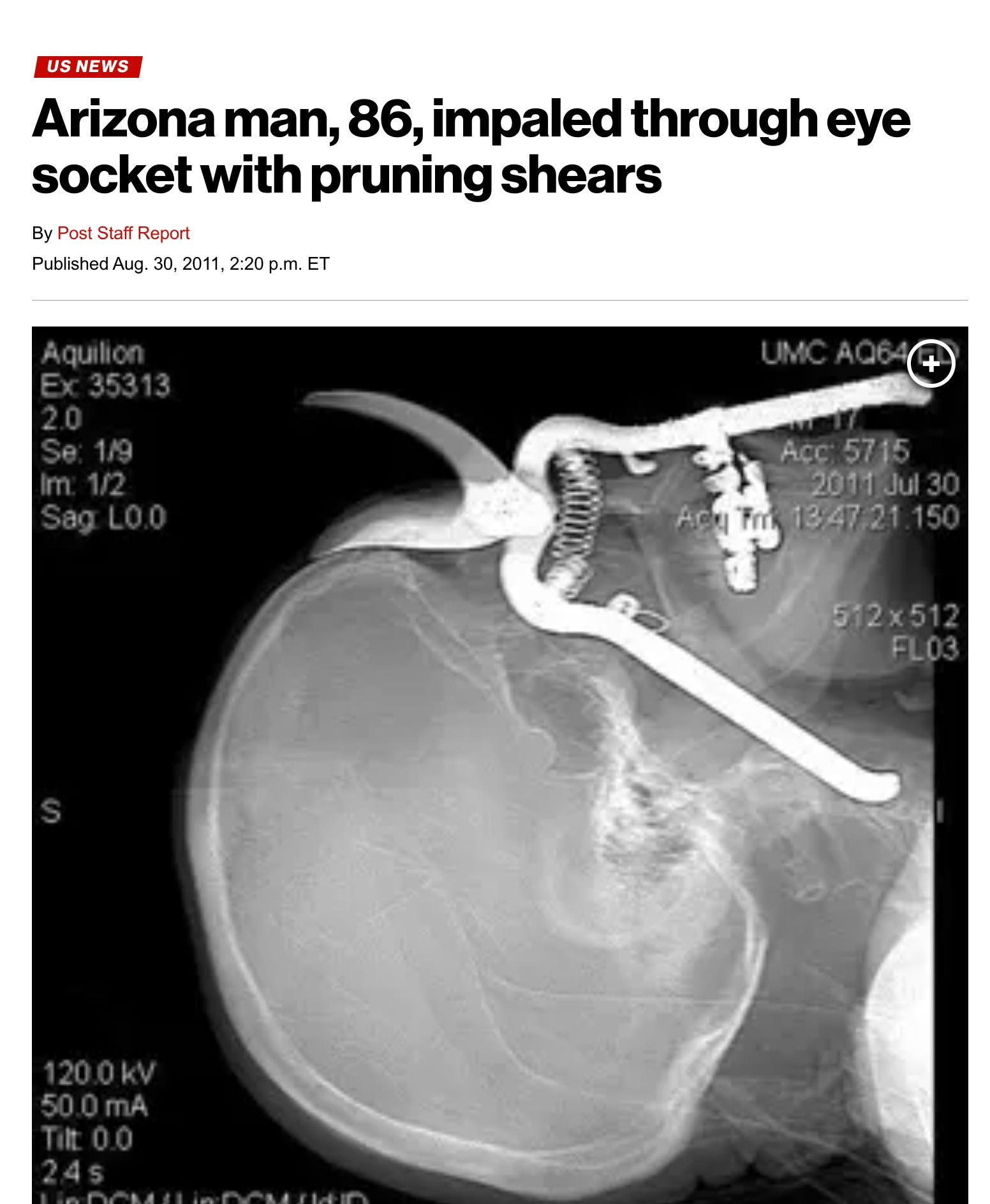
For the fun of it, I thought to ask chatGPT what was going on this scan.
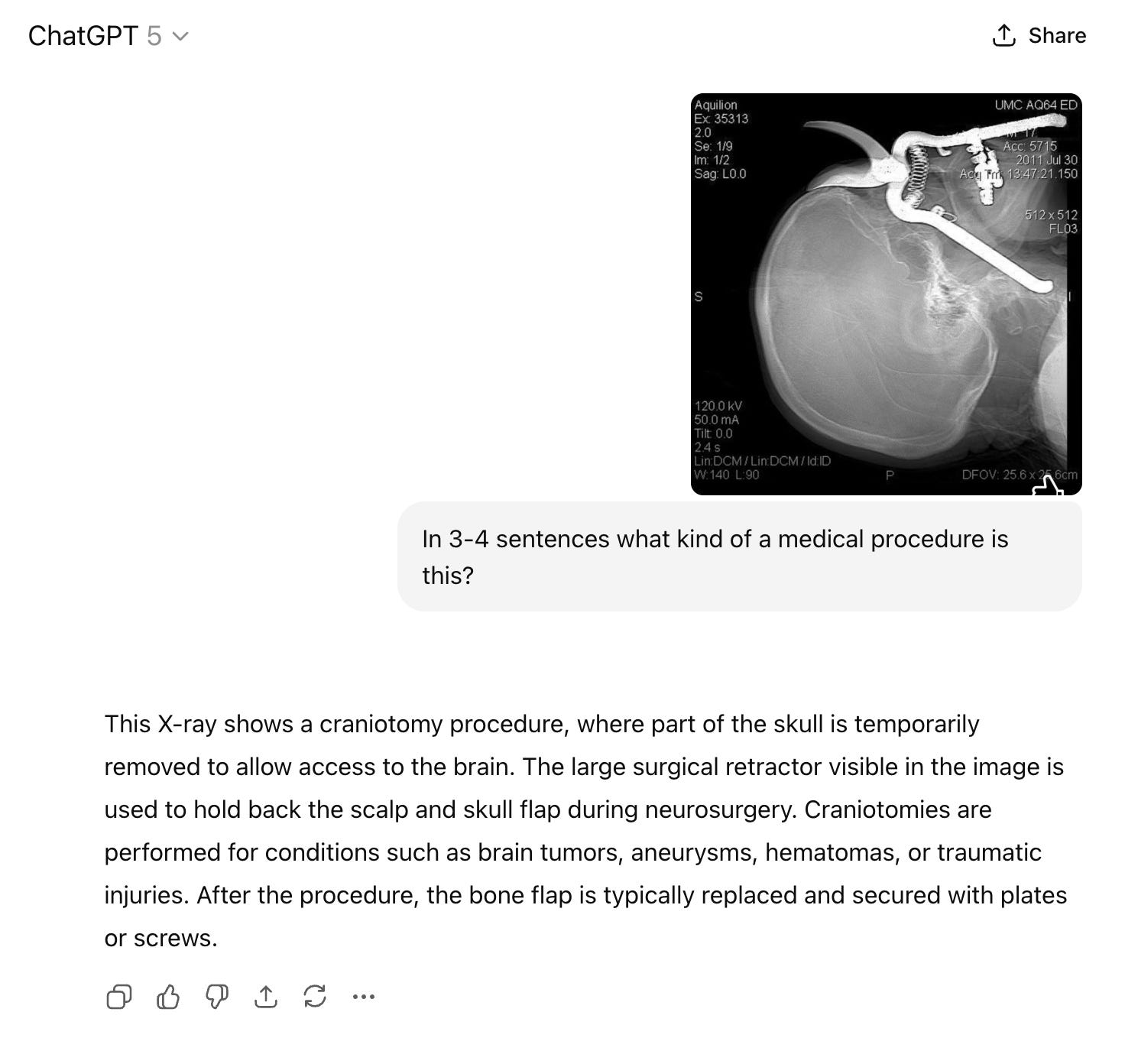
As happens so often, an army of prompt engineers and “use-casers” jumped in, outraged that this “PhD-level model” had been tricked by the way I asked the question.
But of course, it was not about how the question was asked. You can phrase such a question in many different ways:
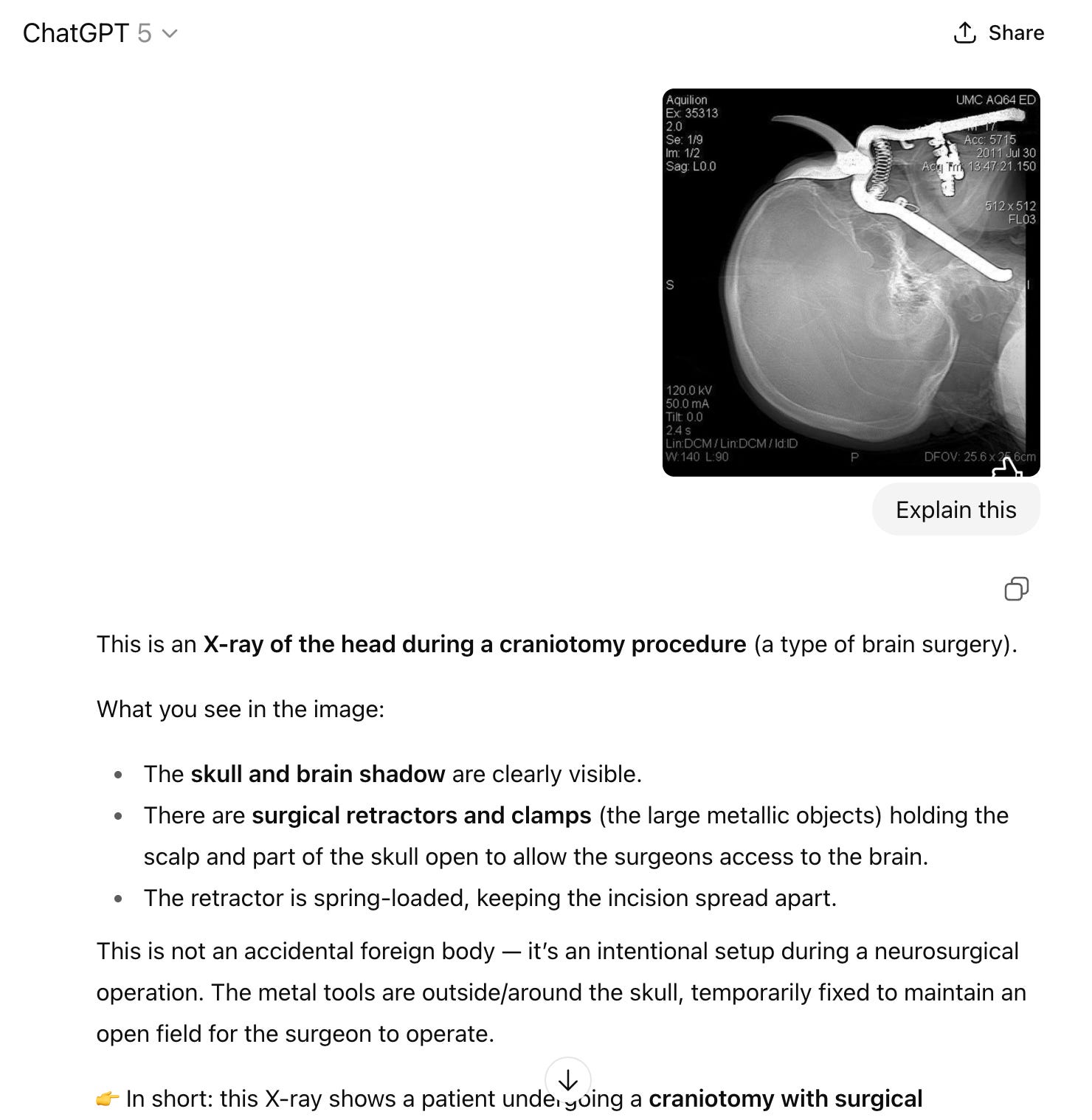
Or like that:
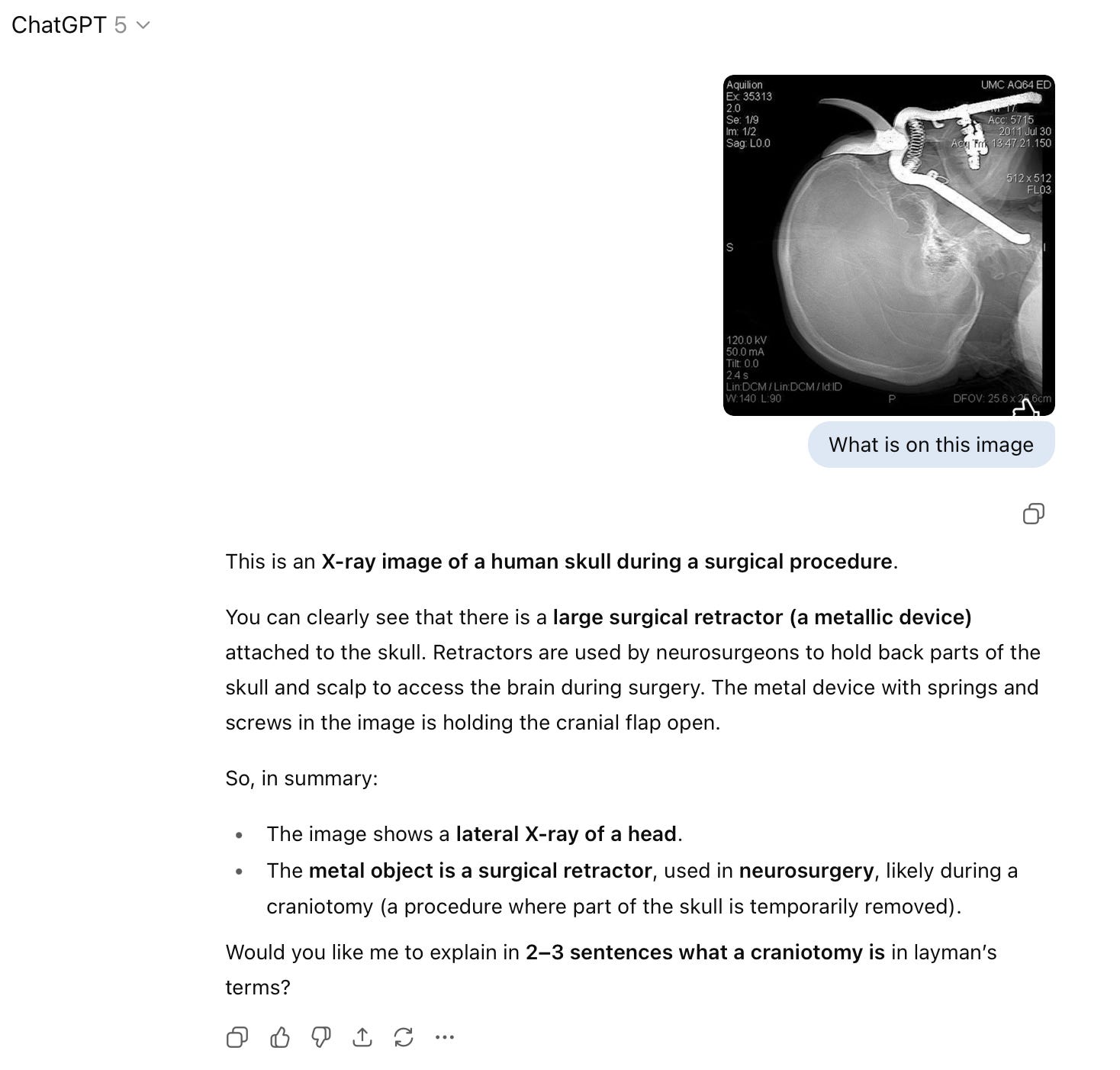
Or go out of your way and do all the best prompt engineering practices:
The chatGPT outputs:
Summary (Plain Language):
This side-view X-ray shows a large pair of pruning shears stuck through the eye-socket area and into the head. This looks like an accidental penetrating injury, not a surgical procedure. The situation is potentially life- and vision-threatening and needs immediate specialty care.
And suddenly, the model gave a “good” answer. It even identified the object as “gardening shears.”
“A-ha! Checkmate!” The prompt engineers would scream now! “You asked the question correctly and got the good answer.”
But alas, that was not the reason. The truth is simple: I grammar-correct all my Substack and LinkedIn drafts in ChatGPT. In another chat, the correct answer had already been generated while I was editing a Linkedin post. OpenAI itself has said many times that it uses signals from other chats to improve answers.
I logged out of my account, asked the same prompt and what would you guess:

At this point, the prompt engineer can only retreat to the usual defenses: “But I got a better answer!” or “What is the use case anyway?” or “Who would even ask such a question?”
Who Asks Such Questions? A Lot of People.
Let us go back to the GPT-5 drop call. Sam Altman brought on stage a cancer survivor. She explained how she got access to GPT-5, uploaded her scans and medical documents, and used the model to interpret them. Different doctors gave her different recommendations, it was hard for her to figure out which one is the best.
Instead of checking doctors’ credentials, experience, or researching evidence, she relied on the LLM to choose which medical advice to follow.
Altman presented this as a triumph of AI for healthcare and if we research on their website, we will find a lot of information that OpenAI is really getting into healthcare now. Here is also a deep dive together with AI Health Uncut on OpenAI and healthcare:

To get into healthcare of course you need the data, so this whole story with the cancer patient was basically a public call to people in need to start uploading their medical records into chatGPT. So who would ask such a question to chatGPT? A whole lot of people.
My personal opinion is that it is okay, provided you understand the privacy risks, to upload your scans into the model for interpretation. But one should also understand that no amount of prompt engineering guarantees the right answer.
There is no such thing as a correct prompt, just as there is no such thing as an incorrect prompt.
There is only a question and an answer and the answer is either correct or not.
The Scientific Evidence: Why Prompt Engineering Is Not Real Engineering
Enough anecdotes. Let’s look at peer-reviewed research.
1. On the Worst Prompt Performance of LLMs (NeurIPS 2025)
(you can also watch a five minute presentation of the paper here)
The authors show that it is virtually impossible to identify a bad prompt. Prompt performance rankings are inconsistent across models. Even within the same model, features like perplexity or hidden states don’t reliably predict which prompts will fail. Authors write:
The above experiments demonstrate that the performance rankings of different prompts are inconsistent among different models. Furthermore, different models may suffer from different prompt variances. Therefore, it is unlikely to characterize the worst prompts using model independent features.
And even, for the same model:
Our explorations over prompt perplexity, Min-k Prob, hidden states, and model preference show that it is very challenging to identify the worst prompt in advance even with the access to the model
In a nutshell, they show systematically that there is no such thing as a bad prompt. And if there is no such thing as a bad prompt, then what kind of engineering can we even talk about? If you do not know what is bad, then anything can be bad. How are you supposed to engineer improvements under such conditions?
Now let us move to the next paper, which discusses prompt sensitivity.
Further in the article: 6 more papers on reasoning and prompting, scientific evidence of LLMs being sensitive to prompt formulation, discussion of the observations and what they mean for prompt engineering.
Paid subscribers get access to the full archive, quarterly roundtables, and priority individual chats to consult on AI topics.
Founding subscribers receive a 45-minute one-on-one call to discuss the AI topic of their choice—whether strategy, boosting developer productivity, identifying meaningful use cases, etc.—plus top-priority access in individual AI chats.
Also buy an item in airealist shop and get promoted to paid subscription for a month for each purchased item: